Adversarially Robust Video Perception by Seeing Motion
Columbia University
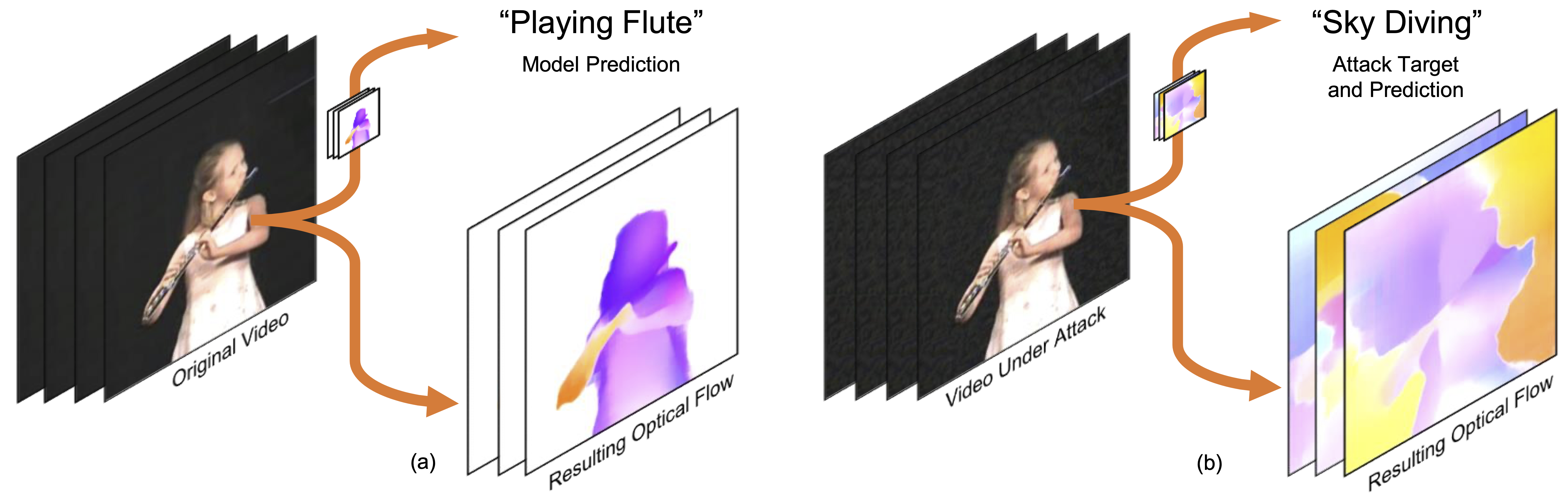
We propose to improve the adversarial robustness of action recognition models by enforcing accurate motion estimation. Adversarial attacks for video perception models often end-to-end optimize the attack noise to fool the classification results. Despite the attack never directly optimizing to change the optical flow, we find they are also collaterally corrupted, as can be seen from (a) to (b). Our work aims to exploit the inconsistencies between the optical flow and the video in order to defend against attacks.
Left: Well-trained optical flow-based action recognition models can accurately classify clean natural videos most of the time. We find that the intermediate optical flow estimation remains accurate and consistent to the video. Because of this, if we used the estimated flows to warp each frame to its previous frame, we can obtain decent reconstruction of the original video. Middle: However, this does not hold true for adversarially perturbed videos. In this case, the flow is corrupted and the warped results are distorted. Right: Our defense updates the input to minimize this inconsistency, resulting in restored flow and corrected classification. Our defense is deployed at inference time and do not require adversarial training or annotations, we improve robustness by merely enforcing motion consistency in a self-supervised manner.
Paper

Abstract
Despite their excellent performance, state-of-the-art computer vision models often fail when they encounter adversarial examples. It has been shown that video perception models are even more fragile under attacks because the adversary has more budget when manipulating high-dimensional data. In this paper, we find one reason for video models' vulnerability is that they fail to perceive the correct motion under adversarial perturbations. Inspired by the extensive evidence that motion is a key factor for the human visual system, we propose to restore this motion information at inference time to correct what the model sees. Since motion information is an intrinsic structure of the video data, recovering motion signals does not require any human annotation. Visualizations and empirical experiments on UCF-101 and HMDB-51 datasets show that restoring motion information in deep vision models improves the robustness under worst-case perturbations. Even under adaptive attacks where the adversary knows our defense, our algorithm is still effective. Our work provides new insight into robust video perception algorithms by using intrinsic structures from the data.BibTeX Citation
@article{zhang2022motion,
title={Adversarially Robust Video Perception by Seeing Motion
},
author={Zhang, Lingyu and Mao, Chengzhi and Yang, Junfeng and Vondrick, Carl},
journal={arXiv preprint arXiv:2212.07815},
year={2022}
}
Acknowledgements
This research is based on work partially supported by the DARPA SAIL-ON program and the NSF NRI award \#1925157. This work was supported in part by a GE/DARPA grant, a CAIT grant, and gifts from JP Morgan, DiDi, and Accenture. We thank Mandi Zhao for discussion. The webpage template was inspired by this project page.